




![图片[2]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/05/1748008145-bb92d7c7fc26bcde325932f5d8c1dde1.png)
![图片[3]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962467-130f9f8e6672073495954fc4821bc0b7.jpeg)
![图片[4]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962468-85456bf22f640e0d8e4811ef665cfbac.png)
![图片[5]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962468-a55420aff6e191a7d8abfc35c2603092.png)
除此之外,DeepSeek-OCR还表现出很高的实际应用价值。在OmniDocBench上,它只使用100个视觉token就超越了GOT-OCR2.0(每页256个token),并且在使用少于800个视觉tokens的情况下,性能超过了MinerU2.0(平均每页近7000个token)。
![图片[6]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962469-29eeddd8534138a8a70519a259e8488a.png)
在生产环境中,DeepSeek-OCR可以每天在单个A100-40G GPU上生成20万页以上的训练数据,为大规模文档理解和多模态模型训练提供支持。
目前,这一模型已在Hugging Face上开源,而介绍DeepSeek-OCR模型技术细节与背后理论的技术报告也已同步公开。DeepSeek-OCR团队称,他们此番开源的模型是对一种潜在解决方案的初步探索,即利用视觉模态作为文本信息的高效压缩媒介。
值得一提的是,与DeepSeek过往新模型动辄数十人的作者团队不同,这篇论文的作者仅有3人,分别为Haoran Wei、Yaofeng Sun、Yukun Li。DeepSeek-OCR论文的第一作者Haoran Wei也是GOT-OCR2.0论文的第一作者,GOT-OCR2.0是阶跃星辰去年9月发布的一款OCR模型。

开源地址:
论文链接:
过去几年,AI模型的上下文能力不断被拉长——从4K到128K,再到上百万token,但代价是成倍增加的算力与显存消耗。
但文本其实是一种冗余的信息形式。DeepSeek-OCR的团队认为:“一张包含文档文本(document text)的图像,可以用比等效数字文本(digital text)少得多的token,来表示丰富信息。这表明,通过视觉token进行光学压缩可以实现更高的压缩比。”
目前,业内已经在VLM视觉编码器和端到端OCR模型上有一定探索。基于此前的研究,DeepSeek-OCR团队发现了目前尚未解决的一个关键研究问题:对于包含1000个单词的文档,解码至少需要多少视觉token?这一问题对于研究“一图胜千言”的原则具有重要意义。
围绕这一问题,DeepSeek打造了一个验证系统——DeepSeek-OCR。该模型通过将文本“光学化”,把原本数千个文字token压缩成几百个视觉token,再由语言模型解码回原文。
DeepSeek-OCR的架构分为两部分。一是DeepEncoder,一个专为高压缩、高分辨率文档处理设计的视觉编码器;二是DeepSeek3B-MoE,一个轻量级混合专家语言解码器。
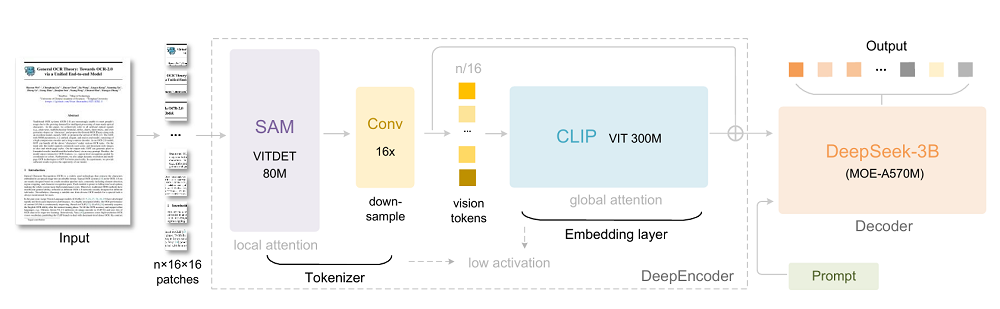
DeepEncoder:显著压缩vision token数量
DeepEncoder采用SAM + CLIP的双结构设计,通过局部窗口注意力结合全局注意力实现高保真视觉理解,并用一个双层的16×卷积压缩模块显著减少vision token数量。
举个例子,当输入1024×1024的文档图片时,传统视觉模型会生成4096个token,DeepEncoder能将其压缩至仅256个token,让激活内存的数量更可控。
此外,它支持多种“分辨率模式”。从轻量的Tiny(64 token)到高保真的Gundam(795 token),模型可根据任务复杂度自动选择压缩等级。
论文展示了不同分辨率的压缩效果。对肉眼而言,Tiny模式下图片中的文字略显模糊,但基本能看清;而在高保真的Gundam模式下,图中文字的阅读体验基本和原文件的阅读体验没有差别。
![图片[7]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962470-433f946d531a1e15f03195d8f97ddb65.jpeg)
▲实际阅读效果需参照原论文中的图片
在实际使用中,一页普通论文或幻灯片仅需100个视觉token即可精准识别;而密集文本的报纸或科学论文,则可通过Gundam模式实现高精度还原。
DeepSeek3B-MoE:激活参数仅5.7B
在解码端,DeepSeek采用自研DeepSeek3B-MoE架构,推理时仅激活6个专家模块,总激活参数量约5.7亿。
这种“按需激活”的机制让模型既具备强表达能力,又能保持低延迟和高能效,极其适合文档OCR、图文生成等场景。
数据引擎:从文档到图表、化学式、几何图
DeepSeek还搭建了一个庞大的数据数据集,包含四大数据类型:
(1)OCR 1.0数据:3000万页多语言文档与自然场景文字等;
(2)OCR 2.0数据:图表、化学公式、几何图形解析等;
(3)通用视觉数据:为模型注入基础图像理解能力;
(4)纯文本数据:维持语言流畅度与上下文建模。
得益于这一体系,DeepSeek-OCR不仅能识字、断句,还能看懂图表、解读化学式、识别几何图形,处理常见的图文交错文档。
当DeepEncoder训练完成后,DeepSeek-OCR团队使用多模态数据和纯文本数据,采用流水线并行策略来训练完整的模型。
![图片[8]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962471-508d7bd265f9ae0d89660a9250e03135.png)
在金融研究报告中,DeepSeek-OCR能自动提取文档中图表的结构化信息,这一功能对金融与科学领域尤为重要。
![图片[9]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962471-f7a46f3d9a6d25fc914ee71d685e7d98.png)
在书籍与论文场景中,深度解析模式能够生成密集的图像描述,实现自动化的图文内容识别与转写。
![图片[10]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962471-9ff8588d6f5edb7196d15676b572fda1.png)
对于化学文献,模型不仅可识别化学结构式,还能将其转化为SMILES格式,展现出在STEM(科学、技术、工程与数学)领域的潜在应用价值。
![图片[11]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962472-2422dbb1bf801577f926a1f45d362fdd.png)
此外,DeepSeek-OCR还能解析平面几何图形的结构,尽管当前任务仍具有较高难度,但模型已显示出对几何要素与空间关系的初步理解能力。
![图片[12]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962473-d3cdc2941daa4c127106eac5b79d0823.png)
互联网上的PDF数据涵盖多种语言,包括中文、英文以及大量多语种内容,这对训练具备全球通用性的大语言模型至关重要。DeepSeek-OCR已具备处理近百种语言的OCR能力,支持带版面与非版面两种输出格式。
![图片[13]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962473-3f6245fb522eda44a1e2268969472ae2.png)
除专注于文档解析外,DeepSeek-OCR还保留了一定的通用视觉理解能力,包括图像描述、物体检测、目标定位(grounding)等任务。在提供相应提示词后,模型能够详细描述图像内容、定位特定对象,甚至在包含文本的图像中执行OCR识别任务。
![图片[14]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962474-79d5e31e879700f2d46b3a322a46fd0f.png)
此外,由于训练中融入了大量纯文本数据,DeepSeek-OCR也保留了较强的语言理解与生成能力。需要指出的是,DeepSeek-OCR尚未经过监督微调(SFT)阶段,因此并非对话模型,部分功能需通过特定提示词激活。
![图片[16]-刚刚,DeepSeek重要突破!大模型上下文紧箍咒打破-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760962475-519784cd767d045d7836f3d907c992ce.png)
<










暂无评论内容