


用Agent一键调用上百个AI项目。
本地极速启动,整合包开箱即用,自动完成环境检测与依赖部署,不必操心构建与配置,专注于结果。
大秦AI 内置多个 AI 整合包与 MCP 能力,一键拉起本地环境,零配置运行。从模型调用到任务编排,你只需一句指令,即可指挥海量智能体并接入任意模型 API。
将百款 AI 项目封装为可一键调用的整合包,覆盖创作、研发、运营与知识管理等场景。瞬间接通模型 API,自由叠加大模型与私有能力。
教程
使用方式一:
AGENT 智能体一键运行
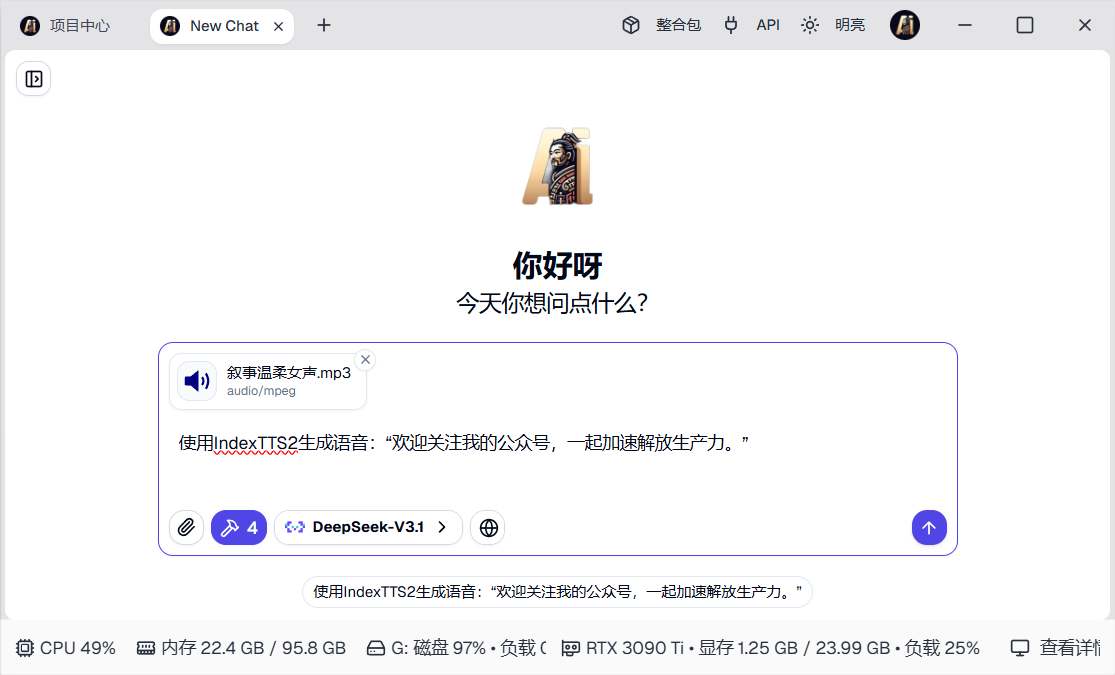
一句话就可以克隆生成语音(使用你上传的声音片段)。
注意⚠️:
此功能需要配置模型 API,如果你有显卡,你甚至可以本地部署 DeepSeek3.2或者Qwen3等开源大模型来完全离线运行,无需联网。
支持本地ollama,同时也支持市面上所有主流 API 服务商:
![图片[1]-25 合1,最新AI语音终极整合包!本地一键运行-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760994222-7908f4217e6fd0295e945bec5e761215.png)
推荐使用GPT、Claude、Gemini最新模型,对于多项目调用,表现更佳。
如果你不懂输入,每个项目都会提供使用示例,你可以点击示例一键跳转生成。
![图片[2]-25 合1,最新AI语音终极整合包!本地一键运行-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760994223-5c1eb143f745392403e530566758e161.png)
使用方式二:
ComfyUI网页运行
![图片[3]-25 合1,最新AI语音终极整合包!本地一键运行-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760994224-55a40cc736e0a2ca08023bc3fd38f0c0.png)
启动后会自动弹出comfyui使用界面,点击侧边工作流按钮,打开对应的工作流,点击运行即可生成。
![图片[4]-25 合1,最新AI语音终极整合包!本地一键运行-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760994225-94fdc8357a14dda6de1aa8743e54509e.png)
更多玩法:
开启公网分享开关(切换到终端tab),会自动弹出网页,把网址分享给你的好友以使用你的显卡执行任务。
![图片[5]-25 合1,最新AI语音终极整合包!本地一键运行-AI Spot](https://www.aispot.com.cn/wp-content/uploads/2025/10/1760994226-d1ca41760cc3fb1d0e74d219aefd928c.png)
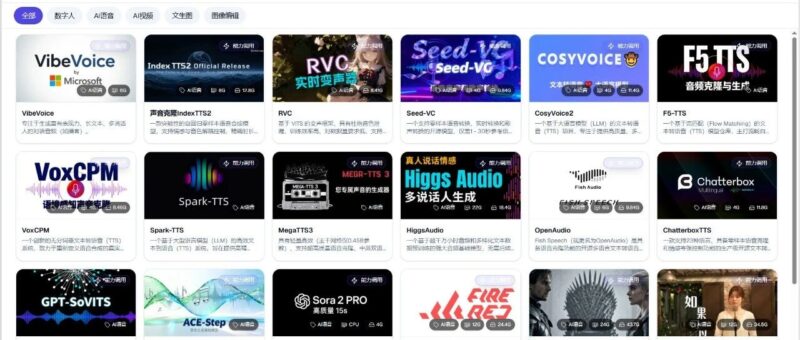
以下是本次《大秦AI》包含的AI语音项目
AI语音项目列表
IndexTTS2
一款突破性的自回归零样本语音合成模型,支持情感与音色解耦控制、精确时长控制及多模态情感引导,在零样本场景下能精准还原目标音色和指定情感,且高情感表达时语音清晰度与稳定性优异。
原始链接:
https://github.com/index-tts/index-tts
节点链接:
https://github.com/diodiogod/TTS-Audio-Suite
F5-TTS
一个基于流匹配(Flow Matching)的文本转语音(TTS)模型仓库,主打流畅自然的语音合成效果。
原始链接:
https://github.com/SWivid/F5-TTS
节点链接:
https://github.com/diodiogod/TTS-Audio-Suite
Higgs Audio V2
一个基于超千万小时音频和多样化文本数据预训练的强大音频基础模型,无需后续训练或微调就在富有表现力的音频生成方面表现卓越,具备多语言多说话者对话生成等罕见能力,还采用了统一音频分词器和DualFFN架构等创新技术。
原始链接:
https://github.com/boson-ai/higgs-audio
节点链接:
https://github.com/diodiogod/TTS-Audio-Suite
MegaTTS 3
具有轻量高效(主干网络仅0.45B参数)、支持超高质量语音克隆、中英双语及代码切换、可控制口音强度等特点。
原始链接:
https://github.com/bytedance/MegaTTS3
节点链接:
https://github.com/billwuhao/ComfyUI_MegaTTS3
CosyVoice
一个基于大语言模型(LLM)的文本转语音(TTS)项目,专注于提供高质量、多语言、低延迟的语音生成能力。
原始链接:
https://github.com/FunAudioLLM/CosyVoice
节点链接:
https://github.com/henjicc/ComfyUI-CosyVoice
OpenAudio (Fish Speech)
Fish Speech(现更名为OpenAudio)是具备语音克隆功能的开源多语言文本转语音项目,拥有高TTS质量、TTS-Arena2最佳排名、丰富语音控制、多语言支持、快速高效等特点。
原始链接:
https://github.com/fishaudio/fish-speech
节点链接:
https://github.com/henjicc/ComfyUI-OpenAudio
Spark-TTS
一个基于大型语言模型(LLM)的高效文本到语音(TTS)系统,旨在提供高精度、自然的语音合成能力。
原始链接:
https://github.com/SparkAudio/Spark-TTS
节点链接:
https://github.com/1038lab/ComfyUI-SparkTTS
VoxCPM
一个创新的无分词器文本转语音(TTS)系统,致力于重新定义语音合成的真实感。
原始链接:
https://github.com/OpenBMB/VoxCPM
节点链接:
https://github.com/wildminder/ComfyUI-VoxCPM
Chatterbox TTS
一款支持23种语言、具备零样本语音克隆和情感夸张控制功能的生产级开源文本转语音模型,基于0.5B Llama骨干网络构建,训练数据达50万小时。
原始链接:
https://github.com/resemble-ai/chatterbox
节点链接:
https://github.com/diodiogod/TTS-Audio-Suite
GPT-SoVITS
一款强大的少样本语音转换与文本转语音工具,支持零样本(5秒语音)和少样本(1分钟数据微调)TTS、跨语言推理。(自带基础模型,如果无法满足需求,还可以自己训练专属模型)
原始链接:
https://github.com/RVC-Boss/GPT-SoVITS
节点链接:https://github.com/smthemex/ComfyUI_GPT_SoVITS_Lite
FireRedTTS2
一个长对话流式文本转语音(TTS)系统,专为多说话人对话与播客/聊天场景设计,能够稳定地在对话中切换说话人、生成上下文感知的韵律并支持零样本语音克隆与多语言(中、英、日、韩、法、德、俄等)及混语场景;当前实现可生成约 3 分钟、4 说话人的对话并可扩展到更长时长,强调超低延迟(利用 12.5Hz 流式语音 tokenizer 与双变换器架构)与高音质/低识别错误率。
原始链接:
https://github.com/FireRedTeam/FireRedTTS
节点链接:
https://github.com/1038lab/ComfyUI-FireRedTTS
VibeVoice
一个创新的无分词器文本转语音(TTS)系统,致力于重新定义语音合成的真实感。
原始链接:
https://github.com/microsoft/VibeVoice
节点链接:
https://github.com/diodiogod/TTS-Audio-Suite
RVC
基于 VITS 的变声框架,具有杜绝音色泄漏、训练效率高、对数据量要求低、支持模型融合、可分离人声伴奏、采用先进音高提取算法且支持多显卡加速等特点。(变声器首选模型)
原始链接:
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
节点链接:
https://github.com/diodiogod/TTS-Audio-Suite
Seed-VC
一个支持零样本语音转换、实时转换和歌声转换的开源模型,仅需1 – 30秒参考语音即可克隆声音,还支持基于少量数据的快速微调。(一键翻唱歌曲)
原始链接:
https://github.com/Plachtaa/seed-vc
节点链接:
https://github.com/billwuhao/ComfyUI_Seed-VC
ACE-Step
一款开源音乐生成基础模型,具备高效生成(A100 上 20 秒生成 4 分钟音乐)、多语言支持(19 种语言)、丰富风格、灵活控制(声音克隆、歌词编辑等)及支持多种衍生应用(如 RapMachine、Lyric2Vocal)等特点。
原始链接:
https://github.com/ace-step/ACE-Step
节点链接:
https://github.com/billwuhao/ComfyUI_ACE-Step
此外还旧版《AI商店》还收录了更多AI语音项目(总计25+)包含声音克隆、AI翻唱、实时变声等,大家可以进入整合包下载地址,自行下载。
整合包下载:
https://openaistore.cn/
作者:
AI秦始皇
<










暂无评论内容